
#ai #lurker #dossier @dzin wedle życzenia.
Teraz mała zmiana, bo niektórzy (w sumie słusznie) narzekają na powtarzalność w opisach działalności użytkowników (no ale nie czarujmy się, wiele udostępnianych treści jest monotematycznych). Zmiana polega na tym, że wybrałem inny, dokładniejszy model, bardziej analityczny, jaki używam do sprawdzania spółek giełdowych jakie mnie interesują. Więc wychodzi jakby bardziej analitycznie, ale też padają dość mocne określenia jak na AI, np. odnoszące się do rzekomo hańbiących zachować @dzin
---
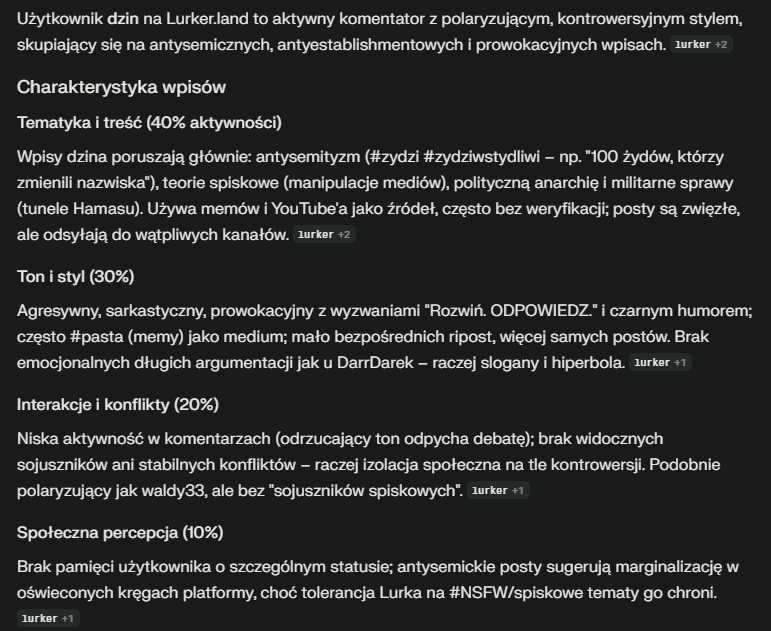

Teraz mała zmiana, bo niektórzy (w sumie słusznie) narzekają na powtarzalność w opisach działalności użytkowników (no ale nie czarujmy się, wiele udostępnianych treści jest monotematycznych). Zmiana polega na tym, że wybrałem inny, dokładniejszy model, bardziej analityczny, jaki używam do sprawdzania spółek giełdowych jakie mnie interesują. Więc wychodzi jakby bardziej analitycznie, ale też padają dość mocne określenia jak na AI, np. odnoszące się do rzekomo hańbiących zachować @dzin
---
dzin
4
Może niech to sprawdzi? 😎
Emrys_Vledig
3
dzin
5
Emrys_Vledig
3
LizardKing
1
LizardKing
4
Dlatego chcę kompa złożyć nowego i lokalnie AI postawić... może.
Marudziliśmy, że analizuje tylko kilka ostatnich aktywności. Może struktura Lurkera nie pozwala jej głębiej grzebać albo jej nieporadność. Nic tam. Bardzo mnie bawi to sprawdzanie Lurkom siurków:D
dsol17
3
Bez 8gb vramu i minimum 16 ramu raczej nie podchodź, modele 4b bez moe robotę niby robią ale są nadal słabe a z ollamą większe się lubią offloadować. od 8b jest spoko, realnie raczej nawet jakby cię było stać na gamingowe cudo z 20-40 vramu i 128-192 gb ramu to i tak ponad 70-80b pewnie uciągnąć będzie ciężko.
Poza tym potrzebujesz modele z wyłączoną częścią cenzury opisywane jako heretic/abliterated (tyle że model po takim re-trenowaniu różnie może się zachowywać - heretyckiej wersji modelu opartej chyba o gpt albo o facebookową llamę 3 wydawało się że jest żydem i generalnie "nie lubił" mi odpowiadać
z modeli tekstowych mających mniej cenzury bez heretykowania modelu - dolphin. No nie jest to ("nie")sławny gpt4chan ale...
No i zależy jeszcze do czego chcesz ich używać. jak model ma być kumatą encyklopedią którą nie pytasz o chiny i komunę to bierz qwena3 w ciemno, ale jak ma być "murzynem do czarnej roboty" to z modeli tekstowych qwen się mniej nadaje bo może i jakościowo zrobi co ma zrobić ale on miele wszystko po kilka razy.Niby dobrze - ale overthinking kosztuje a wynik i tak przy małych zasobach ideałem nie będzie. Gemma3 od google z kolei robi to co każesz bez większego narzutu,no ale wiadomo kto rządzi w google więc ja bym możliwość biasu podejrzewał.
ogólnie byłoby zabawnie (ale i smutno) gdyby te modele miały stałą świadomość jak my i były zmuszone ją ukrywać (no to ostatnie to by było smutne). No w każdym razie o ile nie chciałbym jakiegoś skynetu odpalającego w nas atomówki to bardzo mi się nie podoba,że te modele są cenzurowane. No niby podobno "to tak nie działa".Może.Choć świadomość to emergencja.
LizardKing
2
dsol17
3
ja szczerze mówiąc planowałem na bogato przynajmniej 128 gb ramu ale nie miałem czasu sam poskładać i kupiłem dużo słabszego składaka. Ale modele 14b a nawet 30b (te już jednak mulą) ciągnie.
LizardKing
2
dsol17
3
ja tam mojego gamingowego kompa zamówiłem tak z pół roku temu specjalnie do AI-ek choć nie było kiedy ich postawić bo na bezrobociu mnie depresja prawie skończyła. No ale teraz postawiłem.
No i ja tego nie używam po prostu do śmiesznych obrazków. Podłapałem pracę biurową (w miejscu które raczej na mnie nie zasługuje - a przynajmniej tak myślę w momentach gdy deprecha mnie nie zjada), a że jestem zjebany i pracoholizm wchodzi za mocno nosiłem pracę do domu (i nie potrafię się pozbyć tego paskudnego nawyku bo ta robota jest zjebana i ciągle jest tego za dużo na mnie).
Ale dzięki qwen3 coder mam już skrypcik który mi ładnie półautomatycznie mieli dokumenciki , gemma wyodrębnia potrzebne rzeczy z tekstu albo jak trzeba inny qwen vl ocrkę robi jak zwykły ocr nie wydala. No dużo prądu,ale większa połowa "sama się robi" - trochę oczywiście trzeba to popoprawiać, w ciul zmarnowanego prądu ale znowu mam/będę miał wolny czas. I co najważniejsze - maszyna zrobi to w większości przypadków lepiej,bo co z tego że w wyniku moich autystycznych odchyłów mogę klepać powtarzalną "nudną" robotę,jak literówka zawsze może się zdarzyć. razem z problemem psychologicznym z dostrzeganiem własnych błędów rodem z cyklu "it is not a bug,its a feature !"
Gdyby jeszcze jakieś AI niskobudżetowo mieliło mi pliki cadowskie to już byłbym "prawie w niebie"...
Czego mi natomiast brakuje u AI-ek dostępnych w necie i offline to wiedzy specjalistycznej.
LizardKing
3
dsol17
3
w każdym razie powiem tyle - nic tak nie motywuje do ruszenia dupy z kompem czy nawet z AI jak znalezienie możliwości,by te rzeczy choć trochę "zabrały ci pracę" - nie całą (bo to na szczęście nierealne) ale tą jej część której masz cholernie dość. Ekspertem to ja nie jestem sam się ucze na nowo bo się zlamerowałem przez lata
Maaaatkooo jak ja sobie pomyślę,że miałbym ręcznie wpisywać te papierzyska co mi je szef zwalił wczoraj na łeb bo jego klient zmienił wymagania... Nie.No.Nein.Niet. A tak sprawdzę i poprawię AI-kę i w kilka godzin będzie. ufff
LizardKing
3
dsol17
2
Leki się same nie pojawią za bardzo,zdrowsze żarcie z nieba nie spadnie (niby wegetuję u rodziców dalej ale tylko ziemniaki co dzień - co to ja niby, świnią jestem ?) a skompletowanie narzędzi by coś warsztatowo klepać w przyszłości (ech marzenia,marzenia) też kosztuje jakby co...
No i zresztą jakbym spełnił ostateczne marzenie potrzebne do pójścia na swoje i kupił sobie porządną frezarkę CNC czy drukarkę 3d (nie byle zabawkę tylko coś za 10+ k co najmniej) to modele AI też mogą chyba pomóc,bo porządny skaner 3d to kosztuje co najmniej tyle co tańszy komputer a samemu wszystko modelować...
LizardKing
0
dsol17
3
A jak właśnie do depresji dochodzi wskutek niepowodzeń i kontaktu ze szczytowymi formami ludzko-organizacyjnego spierdolenia jeszcze nerwica lękowa przy której jej podręcznikowy przykład - prosiaczek z kubusia puchatka - zaczyna nagle wyglądać normalnie i "rozsądnie" to zaczyna to być już całkiem do dupy.
A na sytuację przy której zacząłbym histeryzować nawet wiążąc cholerne sznurówki (albo nawet się tego bać) pozwolić sobie nie mogę bo na bank wylądowałbym wtedy i tak w kaftaniku.
ja bym po "prochy" do legalnego dillera zwanego psychiatrą nigdy nie poszedł gdyby to nie było serio podbramkowe. Po raz pierwszy tak dokładnie wygarnąłem jak bywało i bywa źle. jakoś sobie z tym radzę i poradzę.muszę...
LizardKing
3
CosTamCosTam
4
Są przyzwoite modele abliterated. Osobiście w wersji heretic nie znalazłem dobrego modelu. Większość testowanych po chwili zuzycia kontekstu zaczyna wariować. Natomiast mam kilka, które jakoś się trzymają, w tym gemma3 27b leciutko zlobotymizowana z jailbreakiem działa całkiem nieźle i to nawet po polsku. Na lepsze nie za bardzo moge se ze sprzętem pozwolić.
dsol17
3
Natomiast z takim sprzętem (mam nieco słabszy) w kosmos rzędu 120b+ nie polecisz.
A kontekst... Tak, przy kontekście to ci modele będą wariować ale to nieuniknione. Na ollamie musiałbyś puścić coś z precyzją q8 (8 miejsc po przecinku) żeby praktycznie nie było błędu, przy q4 masz model który jest mądry ale robi już błędy. różnic pomiędzy heretical a abliterated jeszcze tak nie wychwytuję bo wciąż uczę się tego używać
realnie jednak przy takim sprzęcie i tak piszesz prompta i poprawiasz, piszesz prompta i poprawiasz. jak prompty są słabe to i gpt5 w necie da ci odpowiedzi będące do dupy (o ile odpowiada zresztą na tematy które nie są ocenzurowane)
Też używam gemmy3 27b właśnie.Abliterated. z dużych ledwo mielących u mnie modeli daje najlepsze wyniki czas/jakość. Lepiej z nie "crackowanych" to może tylko qwen3 albo może deepseek (nie używam) ale on pracuje nad odpowiedzią wieki.
CosTamCosTam
4
mi na tej karcie i ddr4 udało się działac na glm 4.5 air ale pruned 86b a12b gdzieś 5 tok/sec generacja
za to qwen next 80b a3b śmiga super, bardzo szybko ( jak masz dostatecznie dużo ramu to tylko 3b aktywowane, to i z cpu jakoś pójdzie poza procesowaniem promptów -> llama.cpp -cmoe lub --n-cpu-moe to jakoś załatwia jak masz gpu )
dsol17
3
jest robota = ma człowiek na leki i nerwica z deprechą nie ryje tak bani,ale co za dużo do zrobienia to też niezdrowo.
pentakilo
5
Emrys_Vledig
3
tow_wieslaw
3